
<기술 통계>
import pandas as pd
#새로운 데이터프레임 생성
df = pd.DataFrame({'a': [1,2,3,4,5], 'b': [2,4,6,8,10]})
#a와 b의 데이터 요약
df.describe()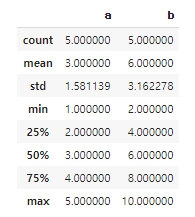
- Mean / Median / Mode
- Range
- Var / SD
- Kurtosis
- Skewness
<추론 통계>
import numpy as np
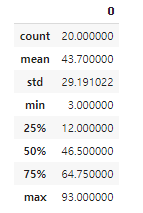
v = np.random.randint(0, 100, 20)
pd.DataFrame(v).describe()
seed() 함수 :: seed 생성
np.random.seed(0)0과 같거나 큰 정수(int)를 넣어준다!
난수를 생성할 때 일종의 기준이 되는 것 : Seed
-> 특정한 시작 숫자를 정해 주면 컴퓨터가 정해진 알고리즘에 의해 마치 난수처럼 보이는 수열을 생성.
시드값은 한 번만 정해주면 된다.
생성된 난수는 다음 번 난수 생성을 위한 시드값이 된다.
rand() : 0과 1사이의 난수를 발생시키는 함수
인수로 받은 숫자 횟수만큼 난수를 발생시킨다.
이때 발생하는 난수는 실수!
#4개의 난수 발생
np.random.rand(4)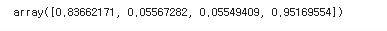
#3행6열에 대한 난수 출력
np.random.rand(3,6)
데이터 샘플링 (data sampling)
numpy.random.choice(a, size=None, replace=True, p=None)
- a : 배열이면 원래의 데이터, 정수이면 arange(a) 명령으로 데이터 생성
- size : 정수. 샘플 숫자
- replace : 불리언. True이면 한번 선택한 데이터를 다시 선택 가능
- p : 배열. 각 데이터가 선택될 수 있는 확률
'Data analysis > Data Process' 카테고리의 다른 글
| Matrix Calculation(Matrix multiplication)/행렬의 연산 Python으로 구현하기 (0) | 2021.01.13 |
|---|---|
| 선형대수 in AI (벡터와 매트릭스vectors and Matrices)/python 파이썬 (0) | 2021.01.13 |
| Hypothesis Test(가설검정) / 기술통계 vs 추론통계 / python 파이썬! (0) | 2021.01.11 |
| Colab환경에서 데이터 분석 진행하기! (데이터 불러오기) (0) | 2021.01.04 |
| Note1 : EDA (데이터 탐색과정이란,,?) (0) | 2021.01.04 |
<기술 통계>
import pandas as pd
#새로운 데이터프레임 생성
df = pd.DataFrame({'a': [1,2,3,4,5], 'b': [2,4,6,8,10]})
#a와 b의 데이터 요약
df.describe()- Mean / Median / Mode
- Range
- Var / SD
- Kurtosis
- Skewness
<추론 통계>
import numpy as np
v = np.random.randint(0, 100, 20)
pd.DataFrame(v).describe()
seed() 함수 :: seed 생성
np.random.seed(0)0과 같거나 큰 정수(int)를 넣어준다!
난수를 생성할 때 일종의 기준이 되는 것 : Seed
-> 특정한 시작 숫자를 정해 주면 컴퓨터가 정해진 알고리즘에 의해 마치 난수처럼 보이는 수열을 생성.
시드값은 한 번만 정해주면 된다.
생성된 난수는 다음 번 난수 생성을 위한 시드값이 된다.
rand() : 0과 1사이의 난수를 발생시키는 함수
인수로 받은 숫자 횟수만큼 난수를 발생시킨다.
이때 발생하는 난수는 실수!
#4개의 난수 발생
np.random.rand(4)#3행6열에 대한 난수 출력
np.random.rand(3,6)데이터 샘플링 (data sampling)
numpy.random.choice(a, size=None, replace=True, p=None)
- a : 배열이면 원래의 데이터, 정수이면 arange(a) 명령으로 데이터 생성
- size : 정수. 샘플 숫자
- replace : 불리언. True이면 한번 선택한 데이터를 다시 선택 가능
- p : 배열. 각 데이터가 선택될 수 있는 확률
'Data analysis > Data Process' 카테고리의 다른 글
| Matrix Calculation(Matrix multiplication)/행렬의 연산 Python으로 구현하기 (0) | 2021.01.13 |
|---|---|
| 선형대수 in AI (벡터와 매트릭스vectors and Matrices)/python 파이썬 (0) | 2021.01.13 |
| Hypothesis Test(가설검정) / 기술통계 vs 추론통계 / python 파이썬! (0) | 2021.01.11 |
| Colab환경에서 데이터 분석 진행하기! (데이터 불러오기) (0) | 2021.01.04 |
| Note1 : EDA (데이터 탐색과정이란,,?) (0) | 2021.01.04 |