
가설검정(Hypothesis Test)
주어진 상황에 대해서, 하고자 하는 주장이 맞는지 안닌지를 판정하는 과정.
모집단의 실제 값에 대한 sample의 통계치를
사용해서 통계적으로 유의한지 아닌지 여부를 판정함.
귀무가설(H0)
- 옳고, 틀리다와 상관없이 표본관찰 -> '이 자료는 이러할 것이다'
ex)00카페에서 제일 많이 팔리는 음료는 딸기바나나스무디 일 것이다.
대립가설(H1)
- 귀무가설에 대립되는 가설 -> 귀무가설이 기각될 때 받아들여지는 가설
ex)00카페에서 제일 많이 팔리는 음료는 딸기바나나스무디 아니다.
귀무가설 귀각(reject) : 가설이 참일 확률이 극히 적어 처음부터 버릴 것이 예상되는 가설.
대립(대안)가설 채택(accept): 연구를 통해 입증되기를 기대하는 예상. 또는 주장하는 내용
이 둘은 목표가 다르다 !
그럼 채택과 귀각의 기준은 ?
이 기준점을 '임계값'(critical value)'라고 한다.
임계값은 유의수준'(level of significance)'으로 부터 알 수 있다.
귀무가설의 기각 여부를 결정하는데 사용하는 기준이되는 확률
제 1종오류를 범할 확률의 허용 한계
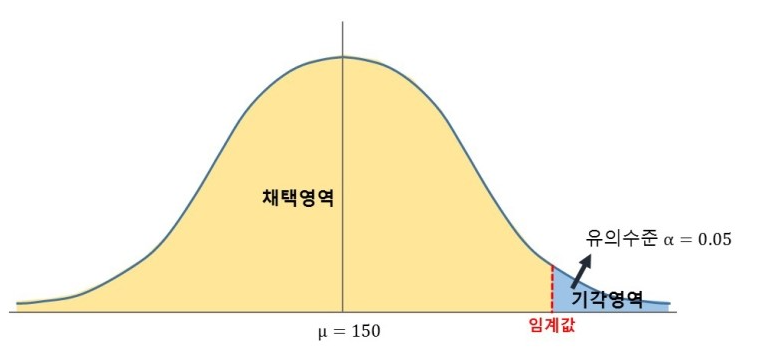
신뢰도 95% -> 유의수준 0.05


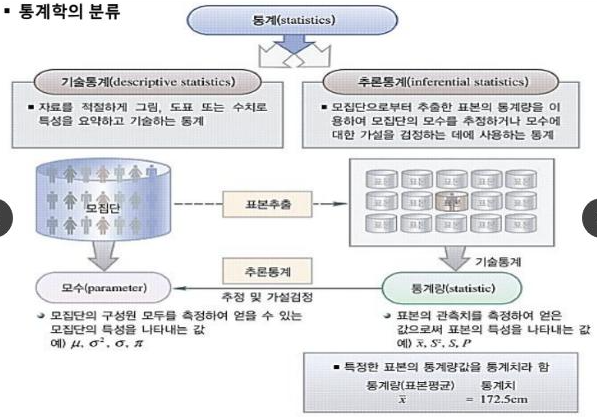
기술 통계치 (Descriptive Statistics) 수집한 데이터를 요약 묘사 설명하는 통계 기법
대표적으로 EDA나 시각화를 예를 둘 수 있다.
우리는, 주어진 데이터로 데이터가 말해주고 있는 바를 직관적으로 알 수 있다.
추론(추정)이 개입되지 않아도 알 수 있는 통계치를 기술 통계치라 할 수 있다.
추정의 단계없이, 표본 추출 과정만으로 데이터를 묘사해 주는 것 .!
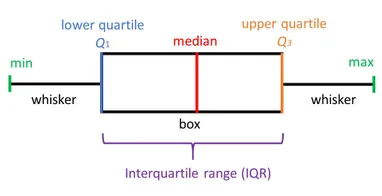
ex)boxplot , bagplot, violin plot
그럼 추리 통계치는 ?
추리 통계치 (Inferetial Statics) 수집한 데이터를 바탕으로 추론 예측하는 통계 기법
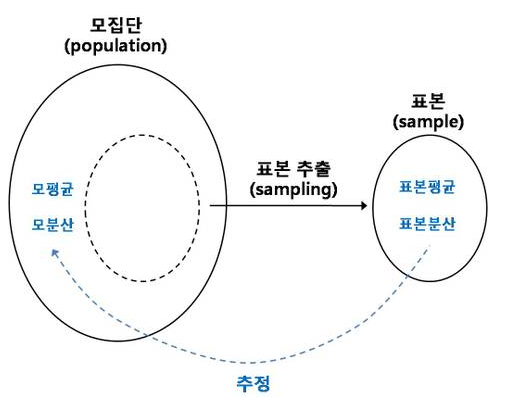
- Population
- Parameter 모수
- Statistic 통계량
- Estimator
- Standard Deviation
- Standard Error
표본의 정보로 모집단을 추측 !!
내가 궁금 한 것은 전체를 알고싶어 샘플링을 한 것이라서,
전체가 알고싶어 작은수를 조사한 것이다. 이 전체를 추론하는 것이 추론통계이다.
코드구현은 다음 글에 ~
'Data analysis > Data Process' 카테고리의 다른 글
| Matrix Calculation(Matrix multiplication)/행렬의 연산 Python으로 구현하기 (0) | 2021.01.13 |
|---|---|
| 선형대수 in AI (벡터와 매트릭스vectors and Matrices)/python 파이썬 (0) | 2021.01.13 |
| Hypothesis Test(가설검정) / Python 코드구현/random.seed()/난수 (0) | 2021.01.11 |
| Colab환경에서 데이터 분석 진행하기! (데이터 불러오기) (0) | 2021.01.04 |
| Note1 : EDA (데이터 탐색과정이란,,?) (0) | 2021.01.04 |
가설검정(Hypothesis Test)
주어진 상황에 대해서, 하고자 하는 주장이 맞는지 안닌지를 판정하는 과정.
모집단의 실제 값에 대한 sample의 통계치를
사용해서 통계적으로 유의한지 아닌지 여부를 판정함.
귀무가설(H0)
- 옳고, 틀리다와 상관없이 표본관찰 -> '이 자료는 이러할 것이다'
ex)00카페에서 제일 많이 팔리는 음료는 딸기바나나스무디 일 것이다.
대립가설(H1)
- 귀무가설에 대립되는 가설 -> 귀무가설이 기각될 때 받아들여지는 가설
ex)00카페에서 제일 많이 팔리는 음료는 딸기바나나스무디 아니다.
귀무가설 귀각(reject) : 가설이 참일 확률이 극히 적어 처음부터 버릴 것이 예상되는 가설.
대립(대안)가설 채택(accept): 연구를 통해 입증되기를 기대하는 예상. 또는 주장하는 내용
이 둘은 목표가 다르다 !
그럼 채택과 귀각의 기준은 ?
이 기준점을 '임계값'(critical value)'라고 한다.
임계값은 유의수준'(level of significance)'으로 부터 알 수 있다.
귀무가설의 기각 여부를 결정하는데 사용하는 기준이되는 확률
제 1종오류를 범할 확률의 허용 한계
신뢰도 95% -> 유의수준 0.05
기술 통계치 (Descriptive Statistics) 수집한 데이터를 요약 묘사 설명하는 통계 기법
대표적으로 EDA나 시각화를 예를 둘 수 있다.
우리는, 주어진 데이터로 데이터가 말해주고 있는 바를 직관적으로 알 수 있다.
추론(추정)이 개입되지 않아도 알 수 있는 통계치를 기술 통계치라 할 수 있다.
추정의 단계없이, 표본 추출 과정만으로 데이터를 묘사해 주는 것 .!
ex)boxplot , bagplot, violin plot
그럼 추리 통계치는 ?
추리 통계치 (Inferetial Statics) 수집한 데이터를 바탕으로 추론 예측하는 통계 기법
- Population
- Parameter 모수
- Statistic 통계량
- Estimator
- Standard Deviation
- Standard Error
표본의 정보로 모집단을 추측 !!
내가 궁금 한 것은 전체를 알고싶어 샘플링을 한 것이라서,
전체가 알고싶어 작은수를 조사한 것이다. 이 전체를 추론하는 것이 추론통계이다.
코드구현은 다음 글에 ~
'Data analysis > Data Process' 카테고리의 다른 글
| Matrix Calculation(Matrix multiplication)/행렬의 연산 Python으로 구현하기 (0) | 2021.01.13 |
|---|---|
| 선형대수 in AI (벡터와 매트릭스vectors and Matrices)/python 파이썬 (0) | 2021.01.13 |
| Hypothesis Test(가설검정) / Python 코드구현/random.seed()/난수 (0) | 2021.01.11 |
| Colab환경에서 데이터 분석 진행하기! (데이터 불러오기) (0) | 2021.01.04 |
| Note1 : EDA (데이터 탐색과정이란,,?) (0) | 2021.01.04 |