

Hbase는 하둡 기반의 분산 데이터베이스이다.
NoSQL분류되어 스키마 변경없이 자유롭게 데이터를 저장 할 수 있다.
HDFS위에서 작동되기 때문에, HDFS의 데이터의 가용성과 확장성을 그래도 이용할 수 있다.
데이터베이스 CAP이론에서 HBASE는 CP타입 (Consistency & Partition tolerance) 시스템으로 구글의 BigData 모델과 유사한 기능을 제공한다.
데이터베이스 CAP 이론
1. 일관성 (Consiostency)
다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것.
이것은 관계형 데이터베이스가 지원하는 가장 기본적인 기능이지만 일관성을 지원하지 않는 NoSQL을 사용한다면 데이터의 일관성이 느슨하게 처리되어 동일한 데이터가 나타나지 않을 수 있다.
각 NoSQL들은 분산 노드 간의 데이터 동기화를 위해서 두가지 방법을 사용한다.
첫째, 데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법이 있다. ( 느린 응답시간을 보이지만 데이터의 정합성을 보장한다.)
둘째, 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음, 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다. (빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생하였을 경우 데이터가 손실될 수 있다.)
2. 가용성 (Availablity)
모든 클라이언트의 읽기와 쓰기 요청에 대하여 항상 응답이 가능해야 함을 보증하는 것. 내고장성이라고도 한다.
3. 네트워크 분할 허용성(Partition tolerance)
지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 두 지역 간의 네트워크가 단절되거나 네트워크 유실이 일어나더라도 각 지역 내의 시스템은 정상적으로 동작해야 함을 의미한다.
Hbase 특징
BigTable 논문의 설명을 그대로 구현하고 있다.
1. 컬럼 단위의 데이터 저장, 압축, 메모리 작업, Bloom 필터등을 제공한다.
2. Hadoop에서 실행되는 MapReduce의 입력/출력을 사용할 수 있다.
3. Apache Pheonix와 같은 소프트웨어를 이용해서 SQL 레이어를 올릴 수 있다.
왜 Hbase는 Column Familiy를 가지고 있을까?
1. Distributed - 컬럼들을 쉽게 분산할 수 있다.
2. Sparse - 희소행렬 방식으로 데이터 저장
3. Column - Oriented 컬럼 단위로 데이터를 읽고 쓸 수 있다.
4. Versioned - timestamp가 기준이 되어 질의시 가장 최근 timestap row를 읽어온다.
5. Non-relational - 관계형 DB의 ACID를 따르지 않는다.
Region
Region은 Hbase에서 수평확장의 기본단위다. (분산 및 가용성의 기본 요소 단위)
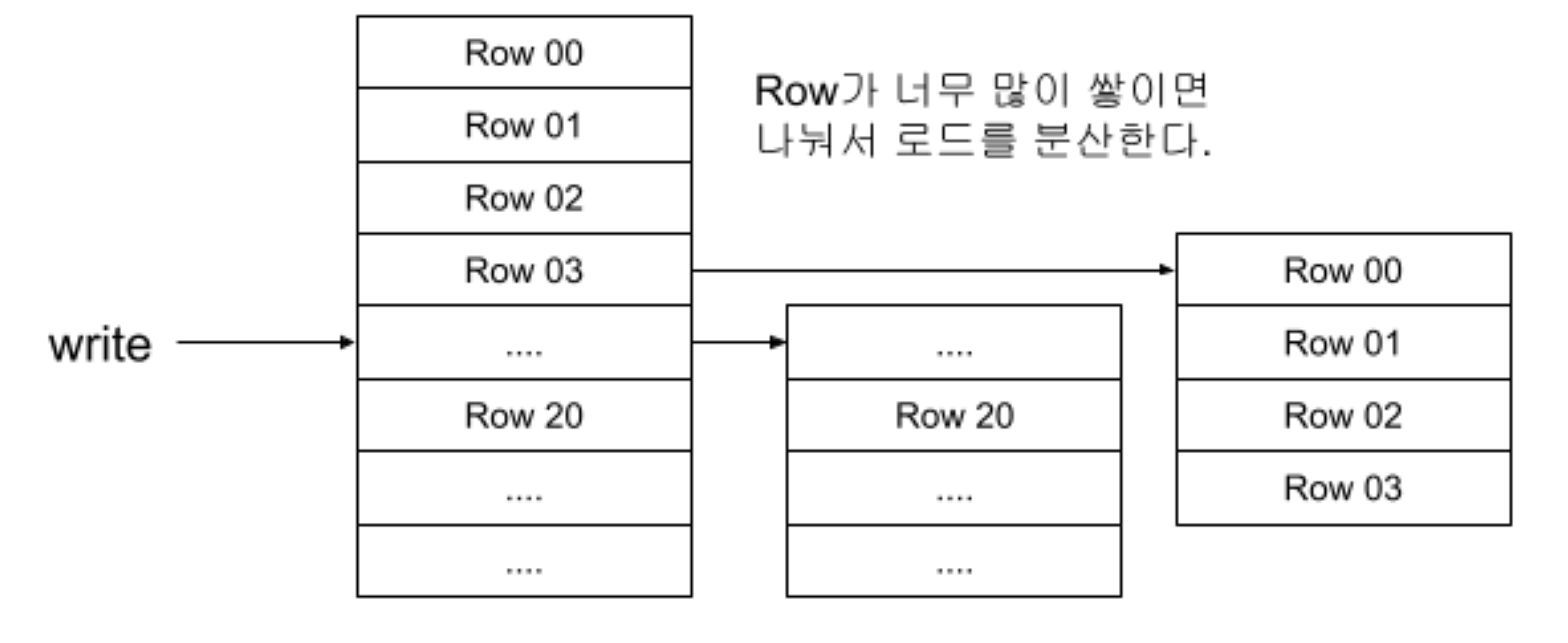
Region은 함께 저장되는 테이블 데이터의 부분 집합이다. 처음 테이블에는 오직 한개의 region만 존자해고, 만약 Region에 많은 row 들이 추가되서 그 크기가 너무 커지면, 중간키를 이용해서 region을 반으로 나눠서 저장한다.
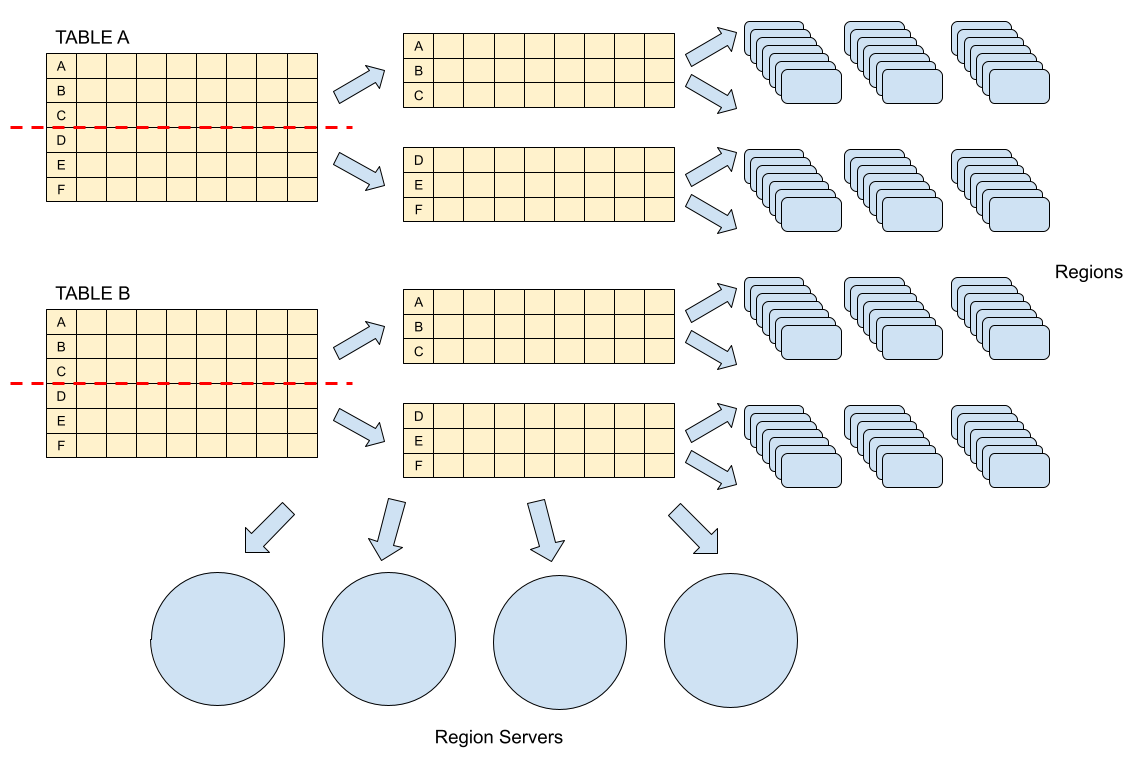
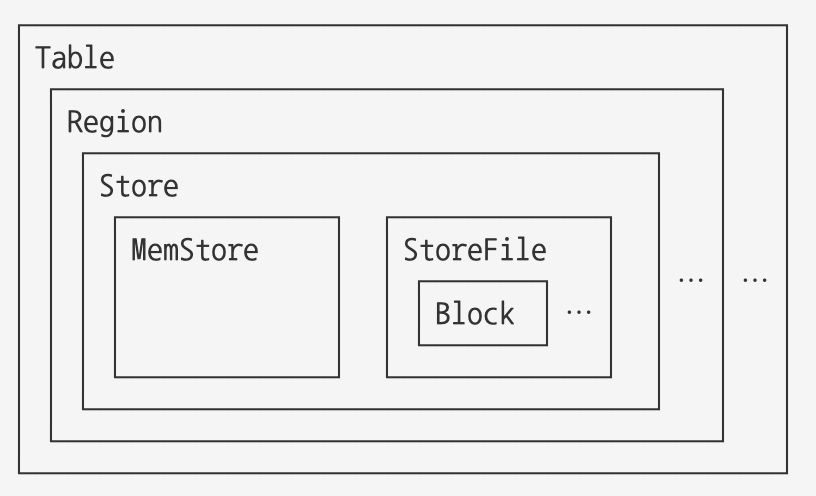
테이블의 로우를 나눠서 수평 분할한 것이 region이라면 Region Server는 이러한 리전을 가지고 있는 서버를 말한다.
Hbase HMaster
각 테이블은 HregionServer가 관리하며, 전체 클러스터는 HMaster가 관리한다.
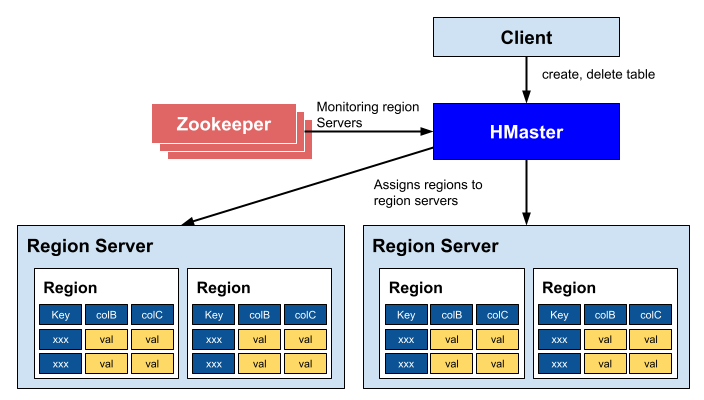
HMaster의 역할
1. 리전 서버들을 조정한다. (관리한다)
- 리전의 시작을 관리. 로드 밸런싱을 위해서 리전을 재 할당하거나 복구하는 등의 일을 한다.
- 클러스터에 있는 모든 리전 서버들을 (주키퍼를 이용해서)모니터링한다.
주키퍼가 리전버서들을 확인 및 모니터링 -> hmaster에게 알린다.
Zookeper : Cluster Coordinator
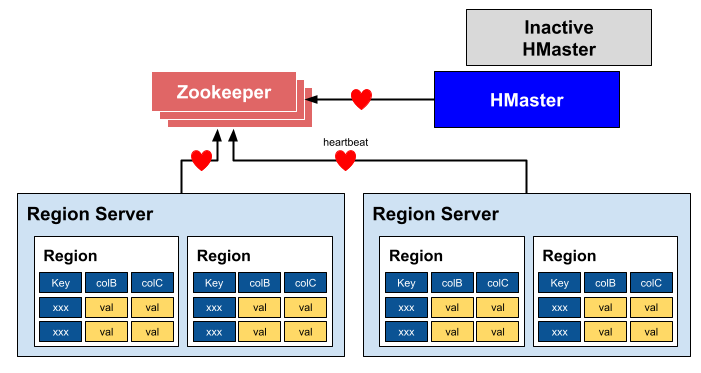
주키퍼는 하트비트를 통해서 이들 노드의 상태를 관리한다.
각 리전 서버는 ephmeral노드로 등록이 된다.
따라서, Hmaster역시 ephmeral로 등록이 된다.
이때. HMaster를 여러노드로 만들때에는 Master/Slave 방식이 된다.
하나의 활성화 HMaster를 제외하고는 나머지는 Slave => 이 또한 주키퍼가 책임진다.
Master/Slave
db 서버의 과부화를 막고 효율적으로 db서버를 운영하기 위해 등장한 것이다.
Slave는 master 서버로부터 복제된 데이터를 받아서 master의 요청들에 대응한다.
그렇다면 서버는 어떻게 데이터를 동기화할까?
- 클라이언트 db 서버 중 마스터 db 서버에 데이터를 보내준다.
- 마스터 서버는 일단 이렇게 들어오는 데이터를 Binary Log라는 메모장에 적어두었다가, 때가 되면 db에 업데이트한다.
- 이 와중에 Slave 서버가 최신 데이터를 요청한다.
- 마스터 서버는 Binary log에 적어둔 최신 정보를 읽어서
- Slave 서버에 전달한다.
- Slave 서버는 이 정보들을 자신의 메모장인 Relay Log에 적었다가
- 나중에 한번에 변경사항을 db에 적어둔다.
- 다른 클라이언트나 서버가 마스터가 저장해둔 데이터를 쿼리로 요청하ㅏ면
- Slave 서버가 동기화된 데이터를 전달해준다.
2부에 계속.
'Data Platform Engineering' 카테고리의 다른 글
| [HBase] 3. HBase Architecture / 읽기, 쓰기 경로 (1) | 2022.10.11 |
|---|---|
| [HBase] 2. META 테이블 / Region Sever Components (0) | 2022.10.11 |
| Data warehouse & Data mart 무슨 차이가 있을까? (0) | 2022.08.23 |
Hbase는 하둡 기반의 분산 데이터베이스이다.
NoSQL분류되어 스키마 변경없이 자유롭게 데이터를 저장 할 수 있다.
HDFS위에서 작동되기 때문에, HDFS의 데이터의 가용성과 확장성을 그래도 이용할 수 있다.
데이터베이스 CAP이론에서 HBASE는 CP타입 (Consistency & Partition tolerance) 시스템으로 구글의 BigData 모델과 유사한 기능을 제공한다.
데이터베이스 CAP 이론
1. 일관성 (Consiostency)
다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것.
이것은 관계형 데이터베이스가 지원하는 가장 기본적인 기능이지만 일관성을 지원하지 않는 NoSQL을 사용한다면 데이터의 일관성이 느슨하게 처리되어 동일한 데이터가 나타나지 않을 수 있다.
각 NoSQL들은 분산 노드 간의 데이터 동기화를 위해서 두가지 방법을 사용한다.
첫째, 데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법이 있다. ( 느린 응답시간을 보이지만 데이터의 정합성을 보장한다.)
둘째, 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음, 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다. (빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생하였을 경우 데이터가 손실될 수 있다.)
2. 가용성 (Availablity)
모든 클라이언트의 읽기와 쓰기 요청에 대하여 항상 응답이 가능해야 함을 보증하는 것. 내고장성이라고도 한다.
3. 네트워크 분할 허용성(Partition tolerance)
지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 두 지역 간의 네트워크가 단절되거나 네트워크 유실이 일어나더라도 각 지역 내의 시스템은 정상적으로 동작해야 함을 의미한다.
Hbase 특징
BigTable 논문의 설명을 그대로 구현하고 있다.
1. 컬럼 단위의 데이터 저장, 압축, 메모리 작업, Bloom 필터등을 제공한다.
2. Hadoop에서 실행되는 MapReduce의 입력/출력을 사용할 수 있다.
3. Apache Pheonix와 같은 소프트웨어를 이용해서 SQL 레이어를 올릴 수 있다.
왜 Hbase는 Column Familiy를 가지고 있을까?
1. Distributed - 컬럼들을 쉽게 분산할 수 있다.
2. Sparse - 희소행렬 방식으로 데이터 저장
3. Column - Oriented 컬럼 단위로 데이터를 읽고 쓸 수 있다.
4. Versioned - timestamp가 기준이 되어 질의시 가장 최근 timestap row를 읽어온다.
5. Non-relational - 관계형 DB의 ACID를 따르지 않는다.
Region
Region은 Hbase에서 수평확장의 기본단위다. (분산 및 가용성의 기본 요소 단위)
Region은 함께 저장되는 테이블 데이터의 부분 집합이다. 처음 테이블에는 오직 한개의 region만 존자해고, 만약 Region에 많은 row 들이 추가되서 그 크기가 너무 커지면, 중간키를 이용해서 region을 반으로 나눠서 저장한다.
테이블의 로우를 나눠서 수평 분할한 것이 region이라면 Region Server는 이러한 리전을 가지고 있는 서버를 말한다.
Hbase HMaster
각 테이블은 HregionServer가 관리하며, 전체 클러스터는 HMaster가 관리한다.
HMaster의 역할
1. 리전 서버들을 조정한다. (관리한다)
- 리전의 시작을 관리. 로드 밸런싱을 위해서 리전을 재 할당하거나 복구하는 등의 일을 한다.
- 클러스터에 있는 모든 리전 서버들을 (주키퍼를 이용해서)모니터링한다.
주키퍼가 리전버서들을 확인 및 모니터링 -> hmaster에게 알린다.
Zookeper : Cluster Coordinator
주키퍼는 하트비트를 통해서 이들 노드의 상태를 관리한다.
각 리전 서버는 ephmeral노드로 등록이 된다.
따라서, Hmaster역시 ephmeral로 등록이 된다.
이때. HMaster를 여러노드로 만들때에는 Master/Slave 방식이 된다.
하나의 활성화 HMaster를 제외하고는 나머지는 Slave => 이 또한 주키퍼가 책임진다.
Master/Slave
db 서버의 과부화를 막고 효율적으로 db서버를 운영하기 위해 등장한 것이다.
Slave는 master 서버로부터 복제된 데이터를 받아서 master의 요청들에 대응한다.
그렇다면 서버는 어떻게 데이터를 동기화할까?
- 클라이언트 db 서버 중 마스터 db 서버에 데이터를 보내준다.
- 마스터 서버는 일단 이렇게 들어오는 데이터를 Binary Log라는 메모장에 적어두었다가, 때가 되면 db에 업데이트한다.
- 이 와중에 Slave 서버가 최신 데이터를 요청한다.
- 마스터 서버는 Binary log에 적어둔 최신 정보를 읽어서
- Slave 서버에 전달한다.
- Slave 서버는 이 정보들을 자신의 메모장인 Relay Log에 적었다가
- 나중에 한번에 변경사항을 db에 적어둔다.
- 다른 클라이언트나 서버가 마스터가 저장해둔 데이터를 쿼리로 요청하ㅏ면
- Slave 서버가 동기화된 데이터를 전달해준다.
2부에 계속.
'Data Platform Engineering' 카테고리의 다른 글
| [HBase] 3. HBase Architecture / 읽기, 쓰기 경로 (1) | 2022.10.11 |
|---|---|
| [HBase] 2. META 테이블 / Region Sever Components (0) | 2022.10.11 |
| Data warehouse & Data mart 무슨 차이가 있을까? (0) | 2022.08.23 |