

처음으로 AI관련된 논문을 준비하고 있다.
논문이라는 것이 말하고자 하는 바는 굉장히 비슷하지만,
세세한 틀은 각 분야마다 상당히 다르게 느껴지는 것 같다.
그래서 내가 먼저 하고자 했던 것은!
논문의 흐름이 어떻게 되나?!! 이걸 먼저 생각해 보기로 하였다.
참고한 논문은
Fine-Grained Action Retrieval Through Multiple Parts-of-Speech Embeddings
2019년 ICCV에 실린 논문이다.
주요 내용은 품사 임베딩을 통한 작업 추출이다.
한마디로 얘기해서 영상에 보이는 모션을 텍스트로 추출해주는 기술을 담은 논문이다.
Abstract
1.우리가 해결하고자 하는 점
We address the problem of cross-modal fine-grained action retrieval between and video
2. 논문에서 소개할 기술
In this paper, we propose to enrich the embedding by disentangling parts-of-speech (PoS) in the accompanying captions. We build a separate multi-modal embedding space for each PoS tag. The outputs of multiple PoS embeddings are then used as input to an integrated multi-modal space, where we perform action retrieval. All embeddings are trained jointly through a combination of PoS-aware and PoS-agnostic losses. Our proposal enables learning specialised embedding spaces that offer multiple views of the same embedded entities.
~~이러한 기술을 제안하여 학습 속도를 높이며, 임베딩 공간을 이용하여 학습할 수 있도록 한다.
3.이러한 기술의 장점.
Results show the advantage of our approach for both video-to-text and text-to-video action retrieval. We also demonstrate the benefit of disentangling the PoS for the generic task of cross-modal video retrieval on the MSR-VTT dataset.
우리 실험 결과는 비디오- 텍스트 or 텍스트 - 비디오 액션 추출에 대해 이점을 보임
또한 ~~ 이러한 장점을 가진다.
Introduction
1.우리의 기술이 필요한 이유
2.기술의 주된 기능
[그림으로 요약]

Figure 1. We target fine-grained action retrieval. Action captions are broken using part-of-speech (PoS) parsing. We create separate embedding spaces for the relevant PoS (e.g. Noun or Verb) and then combine these embeddings into a shared embedding space for action retrieval (best viewed in colour).
기존의 것을 넘어 세분화된 작업 검색을 목표로 한다. (작업검색: 영상에서 행동 추출)
3.기존의 기술보다 나은 이점.
This approach has a number of advantages over training a single embedding space as is standardly done [7, 8, 15, 22, 24]. Firstly, this process builds different embeddings that can be seen as different views of the data, which contribute to the final goal in a collaborative manner. Secondly, it allows to inject, in a principled way, additional information but without requiring additional annotation, as parsing a caption for PoS is done automatically. Finally, when considering a single PoS at a time, for instance verbs, the cor450 responding PoS-embedding learns to generalise across the variety of actions involving each verb (e.g. the many ways ‘open’ can be used). This generalisation is key to tackling more actions including new ones not seen during training.
우리 기술의 접근 방식은 많은 이점이 있다.
(동영상 분석의 이점을 말하는 것이 아닌. 모델 설계에 대한 이점을 주로 작성.)
첫째 : 다양한 임베딩을 구축 (데이터를 다양한 관점에서 볼 수 있음)
둘째 : 추가 정보를 주입할 수 있음
마지막으로 ~란 이점이 있다.
(이러한 이점이 기존의 어떠한 단점을 보완해 줄 수 있는지 서술)
Related Work
다른 사람들의 연구결과를 보여줌
-> 우리 연구결과의 상대적인 위치를 보여줌
(우리의 연구는 다른 A나 B연구를 정확도 00%에서 00%으로 개선하였다.)
또한, 우리는 이러한 부분을 초점 & 강조.
We next describe our proposed model.
자연스럽게 우리가 제안한 모델을 설명하기.
Method
모델로 얻고자 하는 목표
Our aim is to learn representations suitable for crossmodal search where the query modality is different from the target modality. Specifically, we use video sequences with textual captions/descriptions and perform video-to-text (vt) or text-to-video (tv) retrieval tasks. Additionally, we would like to make sure that classical search (where the query and the retrieved results have the same modalities) could still be performed in that representation space.
쉽게말해 우리의 목표는 ~~이런 것
1.모델의 Overview
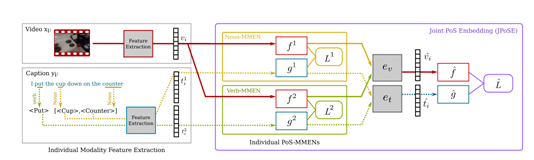
2.모델 설명.(최소 3단계로)
Multi-Modal Embedding Network (MMEN)
Disentangled Part of Speech Embeddings
PoS-Aware Unified Action Embedding
특히 우리는! 모델(기능) 한번 더 강조하기
그러기 위해서 우리가 실험에 적용할 session의 내용을 구체적으로 기술
Experiments
실험을 어떻게 진행하였는지 Process/ 사용된 표본 기술

일반적 실험의 protocol
Result

이 실험을 통해 제안하고자 하는 점.
First, we consider cross-modal and within-modal finegrained action retrieval. Then, we present an ablation study as well as qualitative results to get more insights.
실험을 통해서 얻은 부분.
우리는 실험을 통해서 이러한 결과를 얻었고~ 이 부분이 우리의 접근 방식이 적합하다는 것을 증명해준다.
Conclusion
논문 간략히 다시 중요한 부분 언급
We have proposed a method for fine-grained action retrieval. By learning distinct embeddings for each PoS, our model is able to combine these in a principal manner and to create a space suitable for action retrieval, outperforming approaches which learn such a space through captions alone.
우리는 세분화된 행동 조정을 위해 이러한 방법을 제안
주요 method -> 모델의 장점
-> 어떠한 테스트를 거쳤으며 -> 이 결과를 토대로 어떠한 가능성을 보여주었는지.
모델 적용 가능성
(적용 가능한 case제시)
. We tested our method on a fine-grained action retrieval dataset, EPIC, using the open vocabulary labels. Our results demonstrate the ability for the method to generalise to zero-shot cases. Additionally, we show the applicability of the notion of disentangling the caption for the general video-retrieval task on MSR-VTT
단순히 모델기능을 언급하는 것이 아닌. 앞으로의 적용가능한 범위를 확대하여 일반화의 능력을 언급해 줄 것.
Reference
'HBase 운영 > Natural Language Processing' 카테고리의 다른 글
| 자연어처리(NLP)/ 텍스트 전처리/ 토큰화(tokenizer), 불용어처리(Stop word) / Spacy in Python (0) | 2021.04.14 |
|---|